
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) that aims to enable computers to understand and generate human language. It has become increasingly popular due to the explosion of digital content and communication, including social media, e-commerce, and mobile applications. With NLP technology, machines can analyze, interpret, and respond to human language, which allows them to perform a wide range of tasks, such as language translation, sentiment analysis, content categorization, data analysis, and many more.
As per the latest report published by market research future, NLP’s market worth is expected to reach $ 357.7 Billion by 2030.
What is Natural Language Processing
Natural language processing is a field of computer science and linguistics that focuses on processing human language. NLP enables machines to read, understand, and generate text as humans do. It includes numerous aspects, such as pragmatic, syntactic processing, semantic analysis, and lexical analysis.
The vital aspect of natural language processing is to create algorithms and models that can comprehend the meaning of human language and generate meaningful responses. At its core, NLP translates human language into a structured format that can be processed by machines. Then machines interpret the machine-generated output to create human-readable text. The most commonly found examples of NLP are language translations, Email filters, etc.

How does NLP work?
Analyzing natural language can be accomplished by dividing it into three parts: syntax, semantics, and pragmatics. However, in practice, this distinction is not so clear-cut. When processing natural language, it is crucial to start with tokenization and sentence segmentation. This is because natural language text is often messy and difficult to separate into neat sentences and tokens. Lexical analysis is also a significant step in natural language processing, as it determines the meanings of individual words.
Semantics and discourse-level processing are more abstract and hard to explore. Natural language generation is a less researched area compared to natural language analysis. It can be challenging to determine the starting point for language generation; however, a clear beginning is provided by natural language text. Even so, natural language generation remains a crucial area of research for the future.
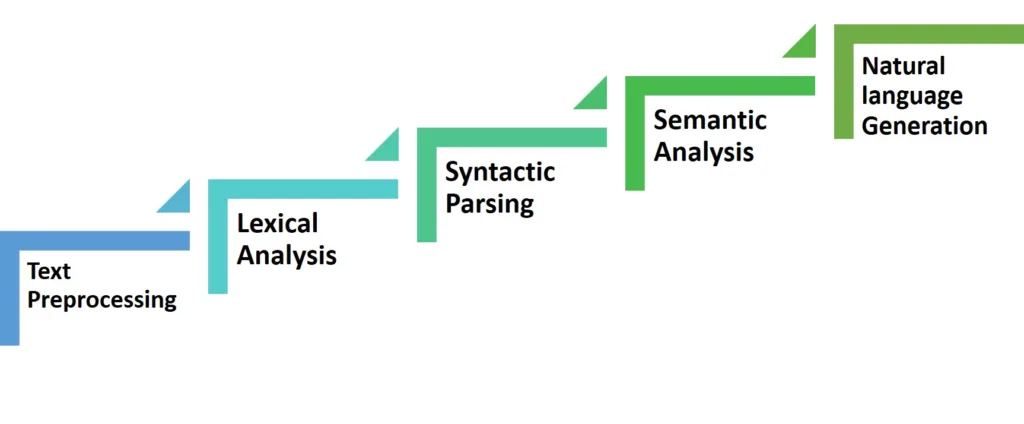
Text Preprocessing
In natural language processing, it’s tough to neatly segment languages into words with spaces. Some languages, like Chinese, Japanese, and Thai require a segmentation before identifying the words in a sentence. However, seemingly easier-to-segment languages like English also have segment and tokenization issues. The underlying problem is determining what constitutes a word.
Sentence segmentation is also challenging since many natural language processing methods focus on sentences. Therefore, it is vital to break a text into sentence-sized pieces. Text preprocessing essentially involves cleaning and transforming raw text into a form that can be used by machine learning and other algorithms. Here are some crucial points to consider:
- Text normalization converts different forms of text into a standard format. For instance, you can use stemming (eliminating a few ending characters out of words) or lemmatization (context analysis) to reduce words to their base forms, such as converting running, ran, and runs to run.
- Stop word removal: Stop words are common words, such as the, a, and an, that do not carry much meaning in a text. These words can be removed during text preprocessing to reduce the dimensionality of the text representation.
- Handling noisy data: It refers to data that has been corrupted or altered in some way, such as text that contains typos, spelling errors, and non-standard language. NLP algorithms can struggle to process noisy data accurately. You can address this issue by using spelling correction tools and text normalization techniques to clean and standardize the text.
- Dealing with rare words: Such words appear infrequently in a structure. These words can be challenging to process, and their rarity can create issues for NLP algorithms that rely on frequently occurring words to extract meaning from text. Techniques such as word embedding and topic modeling can help to capture the sense of rare words by identifying relationships between them and more common words.
- Tokenization: It is the process of splitting text into smaller units or tokens. Tokenization is vital in natural language processingbecause it gives structure to the text, allowing it to be processed more efficiently. There are different tokenization techniques, including word-based tokenization and character-based tokenization.
- Text cleaning: It involves removing unwanted elements from the text, such as HTML tags, URLs, and special characters. Text cleaning can improve the accuracy of NLP algorithms by eliminating noisy data that may interfere with text processing.
- Word disambiguation: Homonyms (words with similar spelling but different meanings) and polysemes (different interrelated meanings of a single word) are words having multiple connotations. Word sense disambiguation determines the correct meaning of a word in a given context. This step is important because it ensures that algorithms are interpreting text correctly.
- Named entity recognition is a technique that involves identifying and classifying named entities such as people, places, and organizations in text. This approach extracts vital information from text, such as identifying company names in customer feedback reviews and improving the performance of NLP algorithms.

Lexical Analysis
The lexical analysis involves breaking down the raw text into individual words or tokens.
- Part-of-speech tagging is a technique used in lexical analysis that involves identifying the grammatical role of each word in a sentence. POS tagging can help improve NLP models’ accuracy by providing additional information about the relationships between words.
- Stemming and lemmatization methods are used to reduce words to their base form. Stemming involves removing the suffixes from words to obtain their root form, while lemmatization acquires the base form of a word according to its meaning and context. These modes can develop NLP models by reducing the number of unique words that need to be processed.
- Handling misspelled words: These words can occur commonly in natural language text. Tools such as spelling correction and phonetic matching (type of speech recognition) can correct misspelled words. These procedures can help to improve accuracy by reducing the impact of spelling errors on text processing.
- Collocation extraction is a method to identify and extract frequently occurring word combinations in a text. These combinations can provide insights into the relationships between different words.
- Language models are statistical models that can predict the probability of a word sequence. In lexical analysis, language models can be used to estimate the probability of a particular word given the context in which it occurs. These models can improve the performance of NLP tasks such as language translation and speech recognition.
Syntactic Parsing
Syntactic parsing is an advanced technique in natural language processing that involves analyzing the grammatical structure of a sentence to identify its constituents and their relationships.

- Dependency parsing is a class of syntactic parsing that involves identifying the dependencies between words in a sentence. This type of parsing is beneficial for tasks such as text classification and information extraction. It can help to elevate the performance of NLP models by capturing the relationships between words.
- Constituent parsing is another kind of syntactic parsing that determines constituents or phrase structures of a sentence, such as noun phrases and verb phrases. It can provide additional information about the grammatical structure of a sentence.
- Tree structures: Syntactic parsing shows the grammatical structure of a sentence using tree structures. These structures are hierarchical representations of a sentence that show the relationships between its constituents, such as the subject, verb, and object.
- Ambiguity resolution: Syntactic parsing can resolve ambiguity in a sentence, such as specifying the correct interpretation of a sentence containing homonyms or synonyms. This can be a challenging job, but various algorithms like machine learning models can pinpoint the accurate analysis of a sentence.
- Domain-specific parsing: In domain-specific natural language processing applications, such as medical or legal text, the language used may be more specialized and complex than standard English.
- Statistical parsing uses statistical models to predict the most likely parse for a given sentence. These models are trained using large corpora of annotated sentences and support for tasks such as text classification and sentiment analysis.
- Role of semantic parsing: It involves assigning meaning to the syntactic structure of a sentence. Semantic parsing can extract information from the text and apply it in areas such as question-answering, semantic search, and dialogue systems.
- Neural network approaches: Recent advances in deep learning have led to the development of neural network models for syntactic parsing. These models use artificial neural networks to learn the dependencies between words and have achieved state-of-the-art performance on various benchmark datasets.
Semantic Analysis
Semantic Analysis is an advanced approach in natural language processing that analyzes the meaning of a text to understand its context and underlying concepts.

- Word sense disambiguation is a process that identifies the correct meaning of a word in a given context. It can be a tedious task due to the multiple meanings of words. In this case, syntactic analysis, machine learning, and semantic networks can boost the accuracy of NLP models.
- Named entity disambiguation is a strategy that specifies entities in a text and determines their type and reference. It can be advantageous for entity recognition, relation extraction, and question-answering.
- A semantic network is a graphical representation of concepts and their relationships. It can help with word sense disambiguation and named entity disambiguation by mapping words to their related concepts.
- Sentiment analysis recognizes the sentiment or emotion expressed in a text. It is especially beneficial for customer feedback analysis and social media monitoring.
- Natural language inference is used in question-answering and information extraction. It determines the logical relationship between two sentences.
- Knowledge graphs are large-scale semantic networks that represent entities, concepts, and their relationships. They also support NLP tasks, such as information extraction, question-answering, and recommendation systems.
- Deep learning approaches, specifically neural networks, have enormously advanced the field of semantic analysis in natural language processing. Neural networks can be used to learn complex relationships between words and help refine performance on tasks such as natural language inference and named entity disambiguation.
- The domain-specific semantic analysis develops models tailored to specific domains such as finance, medicine, or law. This approach can improve the correctness of NLP models in specialized domains by incorporating domain-specific knowledge and language patterns.
Natural Language Generation
Natural Language Generation generates text that is natural-sounding and grammatically correct.

- Template-based generation is a common technique used in natural language generation, where pre-written templates are filled with relevant data to generate new text. This method is valuable for generating text such as weather reports, stock updates, and sports summaries.
- Rule-based generation uses a particular set of rules to generate text based on a set of predefined grammatical structures and language patterns. It is crucial for chatbots and dialogue systems.
- Statistical methods apply machine learning algorithms to generate text. These algorithms are trained on large datasets of text and can create according to various parameters, such as style, tone, and topic.
- Deep learning methods employ neural networks to generate text. These networks can learn to initiate text by analyzing large datasets and knowing patterns in sentence structure and language usage. These methods have led to significant advancements in text generation capabilities.
- Text summarization outlines long texts into shorter, more concise summaries. It can develop areas such as news aggregation and document summarization.
- Language translation translates text from one language to another while doing international communication and cross-language information retrieval.
- Chatbots and virtual assistants often use natural language generation to provide users with responses to their queries and requests. The generated responses should be natural-sounding and grammatically correct in order to provide a positive user experience.
- Creative Text Generation produces new and original text in a given style or genre. This area of research is still developing but has the potential to form creative works of art such as poetry and fiction.
Natural language processing Applications
Natural language processing is used in various applications. Some of the most notable include:
Chatbots and virtual assistants
Chatbots and virtual assistants are becoming increasingly popular these days. These applications use NLP to interpret the user’s request and generate appropriate responses. For instance, personal assistants like Siri and Alexa use NLP technology to interpret the user’s requests and take appropriate actions. While chatbots are utilized in e-commerce and customer service applications to assist customers.

Sentiment analysis
Sentiment analysis involves analyzing and determining the sentiment or opinion of a particular text. This technology is widely used in marketing and social media monitoring operations, as it can help businesses gauge customer sentiment and take appropriate action.
Read our article on the top 5 leading AI Companies and how to select the right one for your business.
Language Translation
Using NLP, machines can translate human languages automatically. Machine translation technology has come a long way, and today’s systems can perform automated translation with a high degree of accuracy.
If you are curious to know about automation, read our post on the top 9 automation facts that are transitioning the world.
Text summarization
Text summarization is generally used in news aggregators, where it generates summaries of news articles. With natural language processing, the text summarizer reads the text and generates a shorter version that captures the key points.
Speech recognition
NLP is used to enable machines to recognize human speech, converting it into a structured format that machines can understand. This method has revolutionized the way we interact with our devices, enabling us to dictate texts and commands to our computers and smartphones.
Challenges in Natural Language Processing
The challenges of natural language processing are many, primarily due to the complexity of human language and the variability in human speech.
Ambiguity
Ambiguity is one of the most significant challenges in NLP. Many words and phrases have multiple meanings, depending on the context. For example, ‘the bank’ can refer to a financial institution or a riverbank. Resolving ambiguity is a complex problem that requires a deep understanding of the context of a particular scenario.
Variability
Human language is highly varied, with different dialects, accents, idioms, and slang. This variability makes it difficult for machines to understand and interpret human language accurately.
Idioms and Sarcasm
Idioms and sarcasm are challenging in NLP, as they require a deep understanding of cultural references and contextual information. For example, the phrase ‘kick the bucket’ means to die, which is a cultural reference that machines may not understand.
Context
Context plays a crucial role in NLP, as it helps machines interpret words and phrases based according to their meaning. However, context can be difficult to establish, making it challenging for machines to understand complex language structures.
Natural Language Processing is a rapidly growing field that holds much promise. With the help of advanced algorithms and computer models, NLP is transforming the way we interact with machines. Despite its many challenges, the future of natural language processing looks bright, and we can expect to see continued advancements in this fascinating field.



Hi Tech Diggers,
First of all above coverage on topic is awesome. I have few queries, kindly let me know how to contact for the same?
Hello Sitesh Kumar, Thank you!
Kindly Email us all your queries. We would be happy to help you.